H2数据库
一些关于H2的其他内容,暂时就不写了。目前就写下如何在Springboot中集成H2数据库。
H2数据库
H2数据库是一个开源的关系型数据库管理系统(RDBMS),它完全用Java编写,这使得H2可以在任何支持Java的平台上运行,且不受平台限制。H2数据库以其轻量级、高性能和灵活性著称,尤其适用于嵌入式环境和小型应用程序,同时也适合于单元测试和开发阶段。
主要特点和功能:
嵌入式与服务器模式:H2既可以直接嵌入到Java应用程序中,也可以作为独立的数据库服务器运行,提供多用户同时访问的能力。
多种运行模式:
嵌入式内存模式:数据仅保存在内存中,重启后数据丢失,适用于不需要持久化的场景,如缓存或临时数据存储。
嵌入式文件模式:数据库存储在本地文件系统中,适合单进程内的数据存储。
兼容性与API支持:H2支持标准的SQL语法和JDBC API,还可以通过模拟模式兼容PostgreSQL的ODBC驱动程序。
事务处理与并发控制:H2提供了事务支持,包括ACID属性,表级锁定机制以及对两阶段提交的支持。
安全性:支持AES加密数据库文件、SHA-256密码加密以及SSL加密通信,确保数据的安全传输和存储。
性能优化:采用基于成本的优化器来提高查询性能,部分复杂查询利用遗传算法进行优化。
轻量级Web控制台:H2包含一个内置的Web控制台工具,可通过浏览器界面管理和监控数据库。
应用场景:
应用程序内嵌数据存储。
快速单元测试。
作为NoSQL缓存,存储关系型且不经常改变的数据。
开发和原型设计阶段的临时数据库替代品。附加特性:支持只读数据库、临时表、可滚动和可更新的结果集、大结果集处理、外部结果排序等高级数据库功能。
实际使用
实际公司改造场景
我们公司有一个跑批系统,用来处理每个主体的数据,根据一个算术表达式来得出一个结果。在本次公司内部系统升级中,对于指标计算的性能提出了明确要求。
最开始的做法:在我入职之前就有的指标跑批系统,对于之前用的将一个指标公式再代码中拆分,然后提取对应的数据,使用JS计算引擎来计算得出结果。效率是很慢的。全量跑一次是按天算的。
重写后的做法: 当时我的预期就是使用
mongoDB这种数据库来处理。但是因为有各种原因,导致无法实施。所以做法是把所有指标公式先做处理,然后将所有数据读到内存中,将数据做成Map<String, Object>的形式,然后使用aviator进行表达式计算。但是这种很慢,因为aviator对于传递进去的表示式并且传递一个Map的参数做运算很慢,特别是需要执行几百万上千万次的时候,这种往往需要几十分钟,甚至几个小时。所以,第二次修改这个的时候,就把公式直接替换成对应的值,丢到aviator中直接做表达式计算,但是就算是这样做,对于几百万的循环来说,仍然需要10分钟左右。最终做法: 将所有需要的数据,按某个主体和年份为维度,做成一个宽表存入H2数据库中。H2数据库以内存的形式启动,本身内存操作就很快了。而且最重要的是H2数据库是支持算术表达式的,我们可以完美的把计算公式直接丢入到sql中。改成这样后,跑批完所有主体所有年份的指标,时间仅仅 30ms!!!!!
Pom文件
<!-- h2 -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>首先我们是基于Springboot应用的,关于Springboot的一些依赖就不放上来了。比如: spring-boot-starter-parent 、 spring-boot-starter-web。
关于一个完整的pom会放到文章的末尾。
Yml
server:
port: 8090
spring:
# 设置数据库信息
datasource:
datasource:
# 参数含义:
# mem | file | tcp 可以指定h2数据库的启动方法,其中mem表示内存启动,file表示本地启动,tcp表示是远程连接
# "jdbc:h2:{ {.|mem:}[name] | [file:]fileName | {tcp|ssl}:[//]server[:port][,server2[:port]]/name }[;key=value...]"
# MODE=LEGACY 指定了模式, LEGACY是兼容模式(兼容版本更新导致的问题),MySql是兼容Mysql的模式,此外还有Oracle、PostgreSQL等
# jdbc:h2:mem:batch_data 表示使用内存模式启动,batch_data则是默认创建这个数据库。 这个地址将作为登录连接console的URL地址
# MODE=MySQL MYSQL模式
# AUTO_RECONNECT=TRUE 连接丢失后自动重新连接
# TRACE_LEVEL_SYSTEM_OUT、TRACE_LEVEL_FILE:输出跟踪日志到控制台或文件, 取值0为OFF,1为ERROR(默认值),2为INFO,3为DEBUG
# DATABASE_TO_UPPER=FALSE;CASE_INSENSITIVE_IDENTIFIERS=FALSE 指定数据库大小写敏感
# AUTO_RECONNECT=TRUE 连接丢失后自动重新连接
# AUTO_SERVER=TRUE 启动自动混合模式,允许开启多个连接,该参数不支持在内存中运行模式
# DB_CLOSE_DELAY=-1 在默认情况下,H2 将会在最后的连接退出的时候关闭数据库。针对基于内存的数据库配置的情况下,如果在这个情况下还进行数据库连接的话,很有可能程序将会得到连接丢失的错误,如果你使用了连接池的话,通常在 JVM 退出之前,连接池都会保持有数据库连接,因此这个问题针对使用连接池的情况可能不存在。如果你没有使用连接池的话,建议将这个参数设置为:DB_CLOSE_DELAY=-1 这样能够保证在虚拟机退出之前 H2 数据库不关闭连接。
# DB_CLOSE_ON_EXIT=FALSE 这个参数的默认配置为 TRUE。在默认情况下,H2 将会在最后的连接退出的时候关闭数据库,如果在这个情况下数据库没有被关闭的话,H2 将会在虚拟机退出的时候关闭数据库。但是在一些特殊的情况下,我们并不希望虚拟机在退出的时候关闭数据库,比如说你还需要使用数据库写入一些虚拟机的情况,或者写入虚拟机的关闭过程等。因此,在这个情况下,你需要讲这个参数配置为 TRUE。
# INIT=RUNSCRIPT FROM ‘classpath:schema/h2.sql’ 初始化 SQL 脚本。
# AUTO_SERVER=TRUE 允许多个进程同时访问数据库.举例来说,如你运行一个测试环境,但是又想用一个 UI 工具来查看数据库中的数据情况,这个时候你需要讲这个配置参数设置为 TRUE。
url: jdbc:h2:mem:batch_data;MODE=MySQL
# h2的驱动为 org.h2.Driver
driver-class-name: org.h2.Driver
username: sa
password:
# 设置h2的控制台等
h2:
console:
# 启用控制台
enabled: true
# 控制台访问路径
path: /h2-console
# 是否可以远程登录
settings:
web-allow-others: true
# 需要设置数据库是否初始化,H2在高版本默认禁止了初始化数据,所以在这里必须设置
sql:
init:
# 加载模式,ALWAYS:始终初始化数据库; EMBEDDED:内存数据库时加载; NEVER: 不加载。
mode: always
# 平台
platform: h2
# 这里设置一个初始化的sql脚本,服务启动后,会自动到resource目录下的db文件夹中找到init.sql执行sql脚本
data-locations: classpath:/db/init.sql
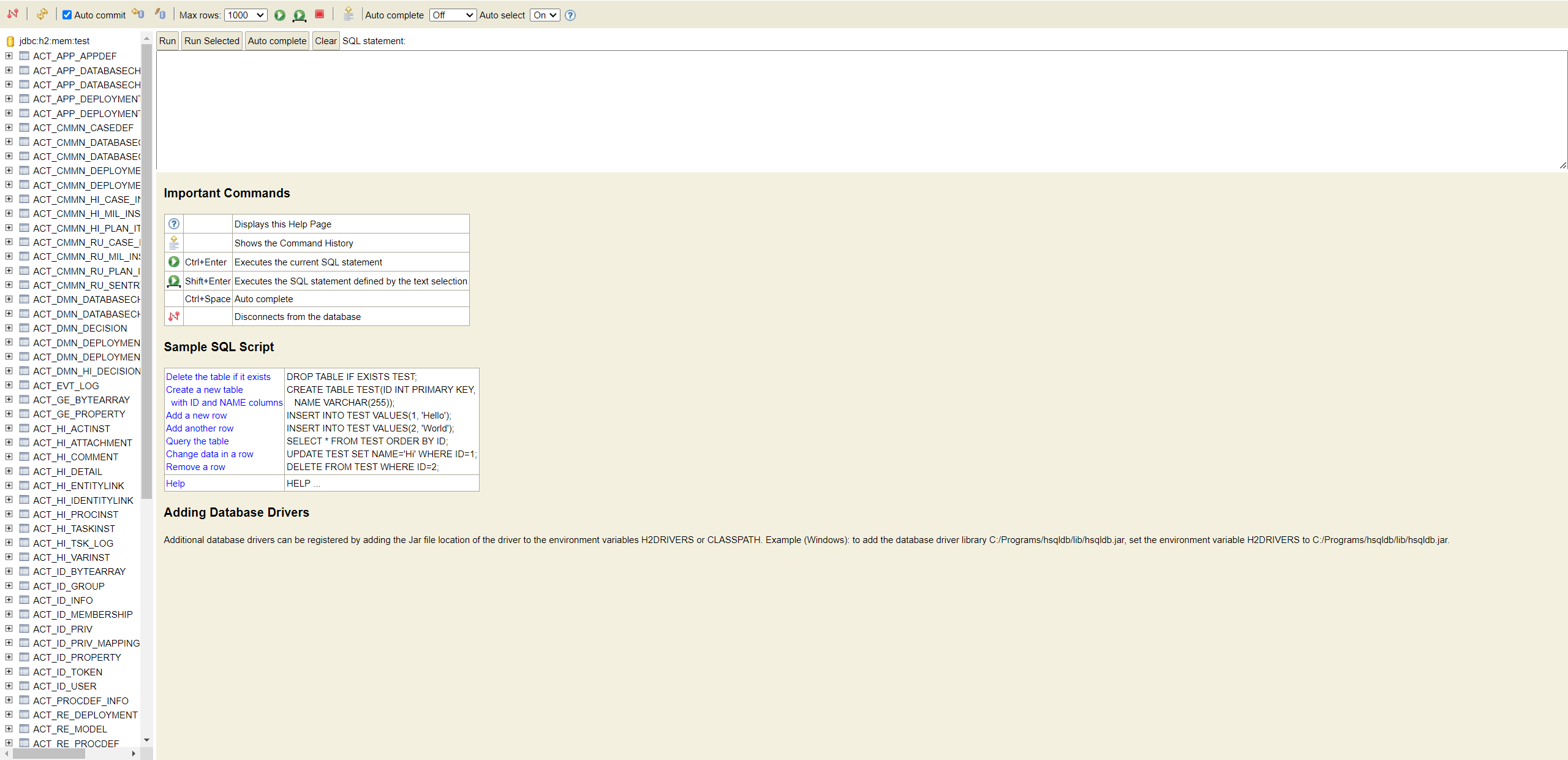
启动成功
登录界面
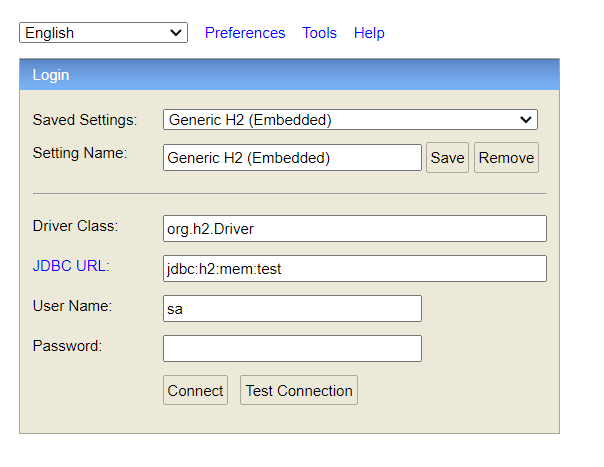 这里需要注意下 JDBC URL,这里根据你启动的模式不同那么内容也不同,如果是内存模式启动,那么就是
这里需要注意下 JDBC URL,这里根据你启动的模式不同那么内容也不同,如果是内存模式启动,那么就是 jdbc:h2:mem:数据库名。
操作界面